Korp tips and tricks: using CQP labels to search for dependency structures
NOTE: This post was originally published on the Språkbanken Text blog. Its target audience is primarily people at my institution and potentially other linguists who already use Korp, our corpus search tool. If you are new to Korp, you can find its user manual here.
This post was inspired by Márton András Tóth’s mid seminar and written in consultation with Martin Hammarstedt.
Say you are a linguist studying the use of present perfect in contemporary Swedish. Surely, you think, Korp has plenty of example sentences.
The present perfect is a compound tense, consisting of the auxiliary har (the present tense form of the verb “to have”) and a main verb in its supine form1. So, you select Extended Search and perform this query:
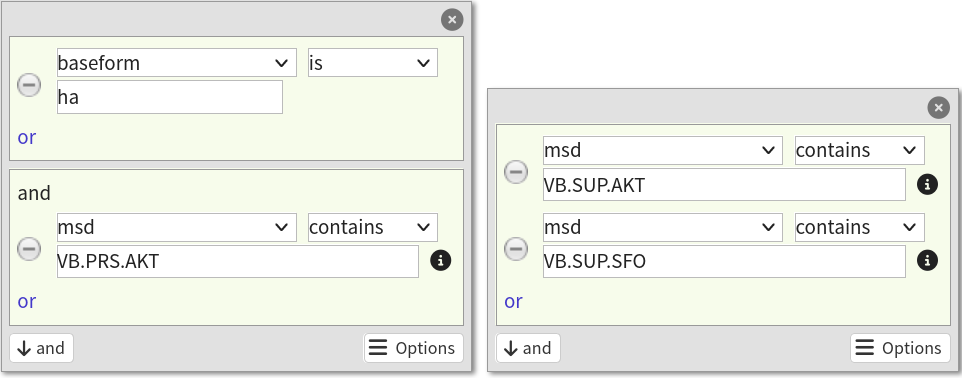
The results look okay, but you quickly realize that your query only allows you to find supine forms immediately preceded by the auxiliary har. You switch to Advanced search and take a look at the CQP query Korp was running under the hood:
[lemma contains "ha" & msd = ".*VB\.PRS\.AKT.*"] [(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*")]
This reads as “find any occurrence of the verb “ha” (lex contains "ha\.\.vb\.1") conjugated in the present tense (msd = ".*VB\.PRS\.AKT.*")2 and followed by a supine (SUP) verb form (VB), active (AKT) or passive (SFO).
If you add an []* between the two tokens, Korp will find all occurrences of har followed by a verb in its supine form, with any number of other tokens in between:
[lemma contains "ha" & msd = ".*VB\.PRS\.AKT.*"] []* [(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*")]
Looking at the results, you start seeing interesting variations, like Men nu har det blivit varmt and Totalt har 438 människor räddats efter stormen. As you scroll down, however, you notice that one of the hits does not really contain a present perfect:
Mannen har HIV och kan ha smittat flickorna.
Of course, this sentence contains both an occurrence of the auxiliary har and a supine, smittat. The problem is that the former does not refer to the latter, which is in turn introduced by the infinitive ha. How to avoid this?
Advanced search with CQP labels
You start browsing the CQP tutorial, looking for a way to use the information Korp provides about dependency relations3. In chapter 4, you find out about labels, which allow giving tokens names that can be used to refer to them later in the query.
The simplest use case for labels is searching for repetitions. Want to find sentences where the same adverb is repeated three times in a row? Then you can just type:
adv:[pos = "AB"] [word = adv.word] [word = adv.word]
This sequence, which matches sentences like
– Det känns väldigt väldigt väldigt bra.
starts with an adverb (AB), labelled adv and followed by two tokens that are identical, with respects to the word form, to adv itself.

But labels can also be useful for searching for specific dependency tree structures. In your case, for instance, you can write:
aux:[lex contains "ha\.\.vb\.1" & msd = ".*VB\.PRS\.AKT.*"] []* [(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*") & dephead=aux.ref]
This query finds any occurrence aux of the present tense of the verb “ha” followed by a supine verb for (active or passive) referring to aux itself (dephead=aux.ref), with any number of tokens in between.
Refining the query
To limit the amount of false positives, it can be a good idea to also specify the correct dependency relation(s) (in this case, both VG (Verb Group) and IV (nonfinite Verb) are admissible):
aux:[lex contains "ha\.\.vb\.1" & msd = ".*VB\.PRS\.AKT.*"] []* [(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*") & dephead=aux.ref & (deprel="VG" | deprel="IV")]
Although a lot less common, there are also present perfect constructions where the auxiliary follows the supine rather than preceding it. You can look for them with a similar query:
sup:[(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*") & (deprel="VG" | deprel="IV")] []* [lex contains "ha\.\.vb\.1" & msd = ".*VB\.PRS\.AKT.*" & sup.dephead=ref]
This has a mere 144 hits on the default corpus selection, many of which arguably annotation errors.
If word order is irrelevant, the two queries can easily be combined with a disjunction (|):
(aux:[lex contains "ha\.\.vb\.1" & msd = ".*VB\.PRS\.AKT.*"] []* [(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*") & dephead=aux.ref & (deprel="VG" | deprel="IV")]) | sup:[(msd = ".*VB\.SUP\.AKT.*" | msd = ".*VB\.SUP\.SFO.*") & (deprel="VG" | deprel="IV")] []* [lex contains "ha\.\.vb\.1" & msd = ".*VB\.PRS\.AKT.*" & sup.dephead=ref]
Notes
-
There are also present perfect constructions where the auxiliary har is omitted, but we will not be discuss them in this post since a finding them requires postprocessing the query results outside of Korp. ↩
-
msdstands for “morphosyntactic description” ↩ -
The dependency annotation scheme used in Korp is specified here. ↩