LyXiG LaTeX
Things that make LaTeX definitely worth it, but that I have to look up every single time:
- Compilers
- Macros
- Resizing stuff to text/column width
- Text size
- Adding a full-page segment to a two-column paper
- Preventing page breaks
- Adjusting margins
- Multiline comments
- SVGs
- Glossed linguistic examples
- Ge`ez and Latin script in the same document
- Generating tables with Pandas
Compilers
| if | then |
|---|---|
| Multiple scripts in the same document | XeLaTeX |
| Springer Nature template | pdfLaTeX |
Macros
Example macro with two arguments that creates a clean version of an unwieldy URL whilst retaining all the https://s and encoded mess in its clickable version:
\newcommand{\cleanurl}[2]{\href{#1}{\nolinkurl{#2}}}
% usage: \cleanurl{https://www.unwieldy.nope}{unwieldy.nope}
Resizing stuff to text/column width
Essentially
\resizebox{\textwidth}{!}{whatever}
% replace \textwidth with \columnwidth as needed
% prepend 0.N to \xxxwidth if the content should be resized to a fraction of the given width
but for tables, the box should be around the tabular and not wrap the entire table environment.
Text size
The standard text sizes are:
\tiny
\scriptsize
\footnotesize
\small
\normalsize
\large
\Large
\LARGE
\huge
\Huge
The normal size can be set document-wise:
\documentclass[Xpt]{class}
Valid values of X for standard classes (article, book, letter and report) are 10 (default), 12 and 13.
To define a custom size:
\newcommand\justright{\fontsize{Xpt}{Ypt}\selectfont}
where X is the font size and Y is the default line skip size.
Adding a full-page segment to a two-column paper
\onecolumn
Preventing page breaks
Create an environment where page breaks are absolutely forbidden (the magic is from StackOverflow):
\newenvironment{nopagebreakswhatsoever}
{\par\nobreak\vfil\penalty0\vfilneg
\vtop\bgroup}
{\par\xdef\tpd{\the\prevdepth}\egroup
\prevdepth=\tpd}
Use it as:
\begin{nopagebreakswhatsoever}
whatever should absolutely be all in the same page
\end{nopagebreakswhatsoever}
Adjusting margins
\usepackage[margin=Xin]{geometry}
Multiline comments
(or something like that)
\iffalse
whatever you don't wish LaTeX to compile
\fi
SVGs
\includesvg{path/to/graphics.svg}
This relies on the following import:
\usepackage[inkscapeversion=auto]{svg}
which in turn relies on having Inkscape separately installed.
Glossed linguistic examples
Add
\usepackage{covington}
and optionally
\setglossoptions{
fspreamble=\scshape\small, % style of the pre-gloss text
fsi=\itshape, % style of the main text
fsii=\normalfont} % style of the gloss
(there is also a bunch of other options, described in the awfully long incredibly thorough covington package docs; these are the ones I most commonly use)
Use as:
\begin{example}
\label{utbildning}
\digloss[preamble=Swedish]
{En bra mening behöver inte vara en bra exempelmening .}
{a good sentence need.PRES not be a good example.sentence .}
{A good sentence is not necessarily a good example sentence. }
\end{example}
which will render as

\triglosses are also possible.
Ge`ez and Latin script in the same document
\usepackage{polyglossia}
\usepackage{microtype, newunicodechar}
\usepackage[sf, bf, big]{titlesec}
\defaultfontfeatures{Scale=MatchUppercase}
\setmainfont{Abyssinica SIL}[Scale=1]
\setsansfont{Libertinus Sans}
\setmainlanguage{english}
\setotherlanguage{amharic}
\newunicodechar{፡}{፡\ }
\newunicodechar{።}{\@{።} }
\newunicodechar{፣}{፣ }
\newunicodechar{፤}{፤ }
\newunicodechar{፥}{፥ }
\newunicodechar{፦}{፦ }
\newunicodechar{፧}{\@{፧} }
\newunicodechar{፨}{\@{፨} }
\newunicodechar{፠}{\@{፠} }
\newfontfamily{\amharicfont}{Abyssinica SIL}[
Script=Ethiopic,
Ligatures=Common,
WordSpace = {0.1,30.0,1.0}]
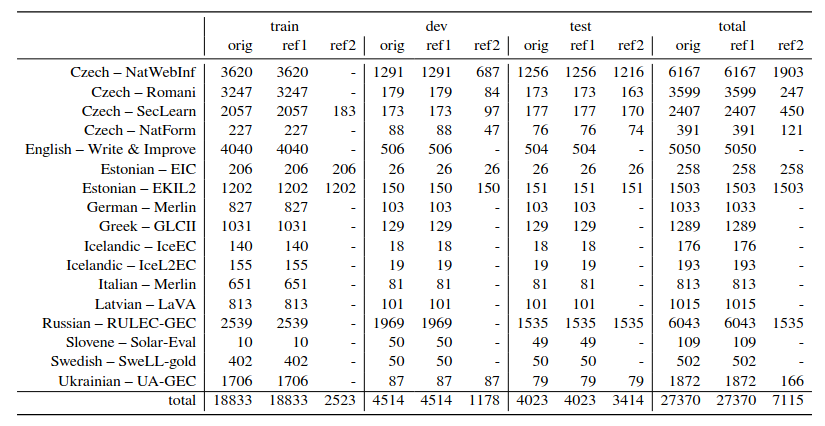
Generating tables with Pandas
Nobody likes LaTeX tables (…right?) and a lot of people use GUI table generators like this. A much more powerful option that handles subcolumns and other annoyances flawlessly is to generate tables with Pandas. This is especially practical when the data to put in the table comes from a Python script.
Basic idea for basic (non-nested) tables: store your data as a DataFrame and run .to_latex() on it.
A dictionary can be easily converted into a DataFrame:
df = pandas.DataFrame(a_dict) # dict -> DataFrame
df.to_latex() # DataFrame -> LaTeX string
Advanced idea for advanced (nested) tables: store your data as a DataFrame of DataFrames, do some mystery reindexing and run .to_latex() on the resulting data structure.
Note that:
-
a
DataFrameofDataFrames can be obtained by concatenating a dictionary ofDataFrames:df_of_dfs = pandas.concat(dict_of_dfs, axis=1) # I don't remember what axis=1 does -
mystery reindexing amounts to running
.reindex():df_of_dfs.reindex(rows)
Working example that is not at all self-contained and I will generalize as soon as I have time:
def build_recap_table(specific_tables):
rows = ["{} -- {}".format(lang.title(), subcorpus) for (lang,subcorpus) in langcorpora] + ["total"]
cols = SPLITS + ["total"]
subcols = ["original_essays", "reference_essays_1", "reference_essays_2"]#, "reference_essays_3", "reference_essays_4"]
nested_data = {}
for col in cols:
col_data = {}
for subcol in subcols:
subcol_data = {}
cross_sub_tot = 0
for (lang, subc) in langcorpora:
row = "{} -- {}".format(lang.title(), subc)
if subcol in specific_tables[lang][subc]["texts"]:
n = specific_tables[lang][subc]["texts"][subcol][col]
else:
n = 0
subcol_data[row] = n
cross_sub_tot += n
subcol_data["total"] = cross_sub_tot
col_data[subcol] = subcol_data
nested_data[col] = pd.DataFrame(col_data)
nested_df = pd.concat(nested_data, axis=1)
nested_df.reindex(rows)
return nested_df
recap_table = build_recap_table(specific_tables)
recap_table.to_latex()
This generates a table that looks more or less like this (modulo some text replacements e.g. to shorten the column names):